47日の夜,Intelは第3世代のXeonスケーラブルプロセッサを正式にリリースしました,つまり、IceLake-SPは長い間,これは、Intel初の10nmプロセスデータセンタープロセッサです。,このプロセッサには最大40コアが搭載されています,前世代と比較して大幅に改善されたパフォーマンス,人気のあるデータセンターでのワークロードの平均46%の削減,新しいプロセッサはプラットフォーム機能も強化します,第3世代Xeonスケーラブルプロセッサは、SGX SoftwareGuardExtensionsが有効になっているIntel初の主流のデュアルソケットデータセンタープロセッサです。,AIアクセラレーション用の暗号アクセラレーションとDLブースト機能もあります。
Intel Xeonスケーラブルプロセッサは、クラウドコンピューティングプロバイダーや大規模なデータセンターを運営している他の企業向けに設計されています,実際、リリース前にテストと展開のためにユーザーに出荷されます。,2021年の最初の数ヶ月で,Intelは200,000以上を出荷しました,今後も出荷を加速していく予定です。すべての主要なクラウドサービスプロバイダーは、IceLakeのサービスを展開することを計画しています,彼らは4月に初めてそのようなサービスを開始します。インテルには50を超える優れたOEMがあります、ODMは、250を超えるIceLakeベースの設計を市場に投入することを期待しています。
第3世代のXeonスケーラブルプロセッサは、実際には2つの部分で構成されています,1つはWhitleyプラットフォームのIceLake-SPです,シングルまたはデュアルのみ,SunnyCoveマイクロアーキテクチャへのCPUコアのアップグレード,元のさまざまなSkylakeベースの派生マイクロアーキテクチャとの比較,サニーコーブはIPCが大幅に改善されました。4ウェイと8ウェイは、少し前にリリースされたクーパーレイク専用です。,これは実際には14nmのSkylake派生物です。

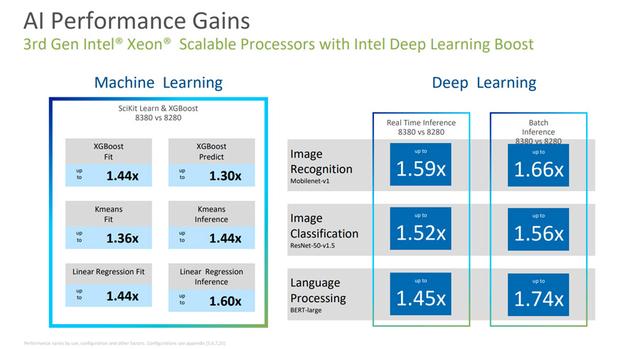
IceLake-SPと前世代のCascadeLakeの比較,コアの最大数が28から40に増加しました,IPCは20%増加しました,そして、全体的なパフォーマンスは46%向上しました,AIのパフォーマンスが74%向上しました,5年前のシステムと比較して,パフォーマンスが165%向上。
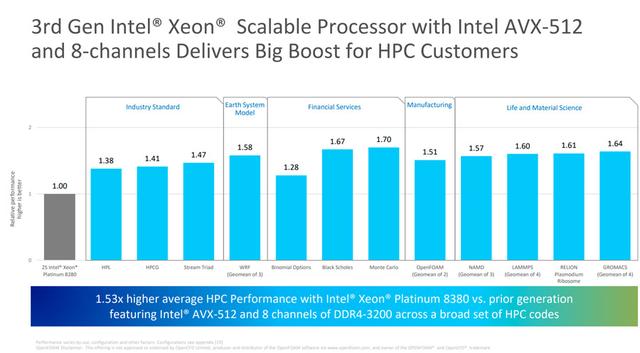
46%パフォーマンスの向上は、標準のベンチマークに基づいています,多くの分野で、実際には50%以上のパフォーマンスの向上が見られます。,クラウドコンピューティングを含む、5G、モノのインターネット、HPC、AIなどの主要な作業分野,これは主に、AIがエッジでますます重要になっているためです,この点でのIceLake-SPのパフォーマンスの向上は非常に明白です。
第3世代のXeonスケーラブルプロセッサのコア数は8コアから始まります,最大40コア,前世代の4コアから28コアへの大幅な増加,アーキテクチャのアップグレードにより、キャッシュアーキテクチャと容量も増加しました。メモリは前世代の6チャンネルDDR4-2933から8チャンネルDDR4-3200にアップグレードされました,最大コンテンツが3TBから4TBに増加したことはありません,Optane永続メモリの最大容量も1.5TBから2TBに増加しました。PCI-Eバージョンが3.0から4.0にアップグレードされました,スロットあたり64のPCI-E4.0レーンを提供するようになりました。UPIチャネルはまだ2から3です,ただし、チャネルあたりの速度は10.4GT/sから11.2GT/sに増加しました,さらに、一連の命令セットのアップグレードがあります。

Ice Lake-SP vs Cascade Lake,アウトオブオーダーリオーダーバッファサイズが224から384に増加しました,レベル1のデータキャッシュが32KBから48KBに増加しました,L2キャッシュが1MBから1.25MBに増加しました,リアエンドは2番目のFMAユニットを導入します,このように、2つの通常のFMA+1つのFMA512ユニットがあります。
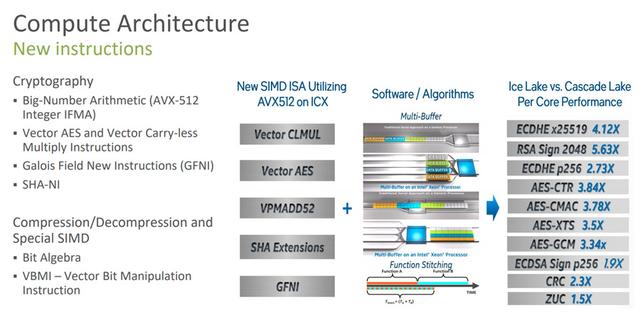
新しいカーネルの登場は、一連の新しい命令セットです。,専用の命令セットを介して,多くの暗号化および復号化計算におけるIceLake-SPのパフォーマンスは、CascadeLakeのパフォーマンスよりもはるかに高くなっています。,最も誇張されているのは5.63倍です。ただし、パフォーマンスの向上を楽しみたい場合は,新しい命令セット用にソフトウェアを再コンパイルする必要があります。
第3世代XeonスケーラブルプロセッサはvAESをもたらします、vPCLMULQDQ命令セット,還有PCI-E 4.0、DDIOなどの新機能,前世代と比較して,広く展開されているさまざまなネットワークワークロード全体で平均1.62倍のパフォーマンス向上。
第3世代のXeonスケーラブルプロセッサのL1およびL2キャッシュレイテンシは、実際にはライバルよりわずかに高いだけです。,しかし、L3キャッシュに関しては、最新世代のEPYC Milanは、依然として1つのioDと複数のCCDで構成されています。,同じダイ内のL3キャッシュレイテンシは非常に低い,ただし、他のDieのL3キャッシュにアクセスするときのレイテンシは非常に高くなります,そして、第3世代のXeonスケーラブルプロセッサは大きなチップです,したがって、L3キャッシュレイテンシは非常に安定しています,さらに、別のソケットCPUにアクセスする場合のL3キャッシュ遅延も、EPYCの場合よりもはるかに低くなります。,自社製品の前世代と比較して、それはまたはるかに低いです。

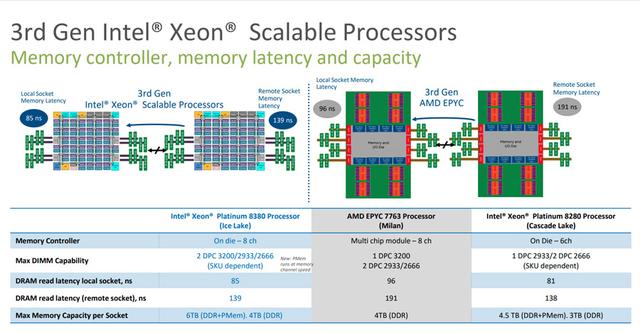
メモリー,8チャネルにアップグレードされた第3世代Xeonスケーラブルプロセッサ,メモリ周波数もDDR4-2933からDDR4-3200にアップグレードされました,そして今、チャネルごとに2つのメモリスロットを埋めることで、周波数を3200MHzに維持できます。,ライバルEPYCミラノシングルスロット3200MHz,デュアルスロット2933MHzと比較して、実際にはより多くの利点があります。メモリレイテンシーに関しては、チャネル数の増加により、レイテンシーは前世代よりもわずかに高くなっています。,しかし、それでも相手よりはるかに低い。容量に関しては、全員の最大容量は4TBです。,ただし、Xeonスケーラブルプロセッサは、追加の2TBのOptane永続メモリをインストールできます,この点でライバルはありません。
第3世代のXeonスケーラブルプロセッサは、命令セットでより多くをサポートしているためです,したがって、コア数が不利な場合でも,しかし、それでも多くの分野で競争をリードすることができます,たとえば、AVX-512をサポートするハイパフォーマンスコンピューティングでは、暗号化、およびDLBoostをサポートするAIアプリケーション。
第3世代のXeonスケーラブルプロセッサに加えて,Intelはまた、会議でOptane永続メモリ200シリーズを紹介しました、Optane SSD P5800X、Intel SSD D5-P5316、Intelイーサネット800シリーズ100Gbpsネットワークカード、コンパニオンQuartusPrime20.4ソフトウェアを搭載したAgilexFPGA,Xeonプロセッサは単なるプロセッサではありません,インテルは、サポートする製品とサービスの完全なセットを提供することもできます,Xeonプロセッサが非常に成功している理由はここにあります。
Intelが2017年に最初のXeonスケーラブルプロセッサを発売して以来,インテルは、5,000万を超えるXeonスケーラブルプロセッサーを世界中のお客様に出荷しています。,世界中のデータセンターに電力を供給。10年以内に,Intelは10億を超えるXeonコアを導入しています,クラウドへの電力供給。そして今日,Intelの見積もりによると,800を超えるクラウドサービスプロバイダーがIntelXeonスケーラブルプロセッサベースのサーバーを導入しています。
コンテンツソース:https://newsroom.intel.com